Munging Data
Skill Builder
Munging Data
Data
Intro to cleaning movies data
This skill builder focuses on munging (formatting) data into a machine learning ready dataset. We will be using an IMDB Ratings dataset. It contains columns that are categorical. Sklearn cannot handle columns that are strings, so we need to convert these into a numerical representation. We accomplish this by either one hot encoding, label encoding, or taking just one value of the range provided. There are many other ways to represent these columns as numbers, but they are beyond the scope of this course.
Once you’ve converted all columns to numeric, in an intelligent way, you will be asked to recreate a graph using Lets-Plot. Here is the head of the data you will be working with. Enjoy!
| star_rating | content_rating | genre | duration | box_office_rev | major_hit |
|---|---|---|---|---|---|
| 9.3 | R | Crime | 142 | €1924521976 - €1925521976 | no |
| 9.2 | R | Crime | 175 | €177034987 - €178034987 | no |
| 9.1 | R | Crime | 200 | €2617541398 - €2618541398 | no |
| 9 | PG-13 | Action | 152 | €996115723 - €997115723 | no |
| 8.9 | R | Crime | 154 | €1172054364 - €1173054364 | no |
Exercise 1
- Grab the high range value for each movie and put it into a new column called
high_range_rev.- Make sure the data type of this new column is numeric!!
- Remove the
box_office_revcolumn from the dataset.
The .str.split() and .astype() methods might be of use! Also, to get the euro sign just copy it from here, €, and put it in your code.
The first 5 rows of the resulting dataframe should look like this
| star_rating | content_rating | genre | duration | major_hit | high_range_rev |
|---|---|---|---|---|---|
| 9.3 | R | Crime | 142 | no | 2345444803 |
| 9.2 | R | Crime | 175 | no | 2182412593 |
| 9.1 | R | Crime | 200 | no | 1604872807 |
| 9 | PG-13 | Action | 152 | no | 284317976 |
| 8.9 | R | Crime | 154 | yes | 1791932201 |
Exercise 2
Convert the major_hit column to 1/0’s. yes -> 1 and no -> 0. Again, there are several ways to accomplish this. Using our old friend np.where is probably the easiest though.
The first 5 rows of the resulting dataframe should like this
| star_rating | content_rating | genre | duration | major_hit | high_range_rev |
|---|---|---|---|---|---|
| 9.3 | R | Crime | 142 | 0 | 1925521976 |
| 9.2 | R | Crime | 175 | 0 | 178034987 |
| 9.1 | R | Crime | 200 | 0 | 2618541398 |
| 9 | PG-13 | Action | 152 | 0 | 997115723 |
| 8.9 | R | Crime | 154 | 0 | 1173054364 |
Exercise 3
Convert the content_rating column using label encoding. We’re using label encoding in this case because the movie ratings already have a natural ordering to them. We will replace each rating with a number in it’s natural ascending order.
To be more specific, here is how we will do it.
- G: 0
- PG: 1
- PG-13: 2
- R: 3
A dictionary and the .map() method could be useful for this exercise. There are other ways of tackling this problem though. Be creative!
The first 5 rows of the resulting dataframe should look like
| star_rating | content_rating | genre | duration | major_hit | high_range_rev |
|---|---|---|---|---|---|
| 9.3 | 3 | Crime | 142 | 0 | 1925521976 |
| 9.2 | 3 | Crime | 175 | 0 | 178034987 |
| 9.1 | 3 | Crime | 200 | 0 | 2618541398 |
| 9 | 2 | Action | 152 | 0 | 997115723 |
| 8.9 | 3 | Crime | 154 | 0 | 1173054364 |
Exercise 4
The last column that we need to take care of is genre. We will use one hot encoding for this. Make sure to ONLY one hot encode the genre column!
A useful function for one hot encoding is pd.get_dummies(). I recommend checking out the documentation.
The resulting dataframe should look like the following example; don’t worry if your high_range_rev column turned into scientific notation—Pandas does this sometimes.
| star_rating | content_rating | duration | major_hit | high_range_rev | genre_Action | genre_Adventure | genre_Animation | genre_Biography | genre_Comedy | genre_Crime | genre_Drama | genre_Family | genre_Fantasy | genre_Horror | genre_Mystery | genre_Sci-Fi | genre_Thriller | genre_Western | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9.3 | 3 | 142 | 0 | 1.92552e+09 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 9.2 | 3 | 175 | 0 | 1.78035e+08 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 9.1 | 3 | 200 | 0 | 2.61854e+09 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 9 | 2 | 152 | 0 | 9.97116e+08 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 8.9 | 3 | 154 | 0 | 1.17305e+09 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
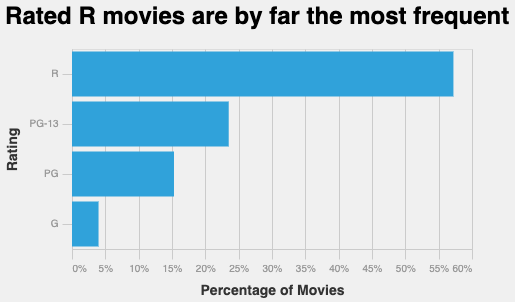
Exercise 5
Recreate this graph as best you can. You’ll need to use the original data that specifies the actual rating.
See the script.